Я недавно случайно наткнулся на интересную статью “УКРОП И ВАТНИК: “язык вражды” российско-украинского конфликта как нападение и защита” [1]. После её прочтения у меня возникли некоторые критические замечания к ней, которыми я бы хотел тут поделиться.
Если совсем коротко, эта статья о дисфемизмах (“обзывалках”) применяемым во время российско-украинского конфликта в 2014-2015 годах. В первой части статьи рассказывается о происхождении конкретных дисфемизмов, а затем проводится анализ их применения. Я хотел бы остановиться именно на второй части – измерение и анализ частоты дисфемизмов в интернете.
Авторы проводили, цитата, “мониторинг интернет-бытования текстов с лексемами “языка вражды””. В качестве инструмента измерения был выбран онлайн сервис “Яндекс. Поиск по блогам”. Далее мои замечания.
1. Online не равно offline.
Первое замечание – авторы никак не подчёркивают тот факт, что результаты их исследования относятся именно к интернет общению, так как именно его они исследовали. Интернет общение если и является “зеркалом” общения вообще, то довольно кривым, как минимум из-за различия аудиторий в категориях возраста, образования и пр. Так например, активные пользователи социальных сетей и блогов в среднем более молодые и образованые [2]. Логично ожидать от этой группы статистически другой лексики, чем от среднего обывателя. Следовало явно указать это, например в summary.
2. Проблемы с инструментом измерения.
Когда проводится исследование с использованием измерений, исследователь должен знать параметры своего измерительного устройства. В особенности такой критичный параметр, как точность измерения. Возможные погрешности обязательно указываются затем в результатах. Без этого научное исследование таковым не является. Будущих исследователей этому учат на первом курсе университета.
Возможно авторы полагали, что применяемый ими сервис “Яндекс. Поиск по блогам” имеет абсолютную точность, а их результаты нулевую погрешность. Это единственное приходящее на ум объяснение отсутствия указаний возможных погрешностей. Хотя и в этом случае авторам стоило так и написать, с указанием источников своих предположений.
К сожалению, погрешности у сервиса “Яндекс. Поиск по блогам” конечно есть, и в этом легко убедиться. Этот сервис работает и сейчас, им можно воспользоваться по адресу http://blogs.yandex.ru .
2.1 Избирательная неполнота.
Наверное не существует сегодня поисковой системы, которая могла бы найти действительно вообще все, что есть в интернете, и “Яндекс” не исключение. Например, “Яндекс” индексирует далеко не все комментарии в блогах. Возьмём для теста случайный пост пятилетней давности случайного блога: https://crusandr.livejournal.com/165422.html . Сам пост достаточно старый и, конечно, проиндексирован. Проиндексированы и часть комментариев, но только из “первого уровня”. Вот пример непроиндексированного комментария из этого поста: https://crusandr.livejournal.com/165422.html?thread=7205678#t7205678 . Ниже приведены скриншоты этого комментария и результата поиска на “Яндексе”.
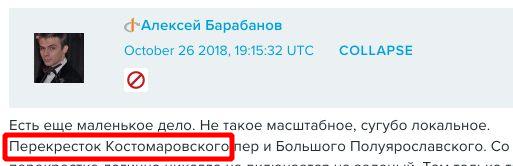
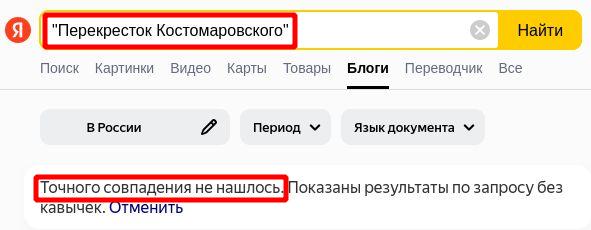
Можно предположить, что длинные “лесенки” комментариев в горячих дискуссиях содержат довольно много дисфемизмов, причём с иным распределением по сравнению с непосредственно постом . Таким образом, игнорирование таких комментариев возможно существенно искажает статистику.
2.2 Неточность в количестве найденного.
“Яндекс”, так же как и “Google”, показывает лишь приблизительное количество результатов поиска. “Google” пишет об этом прямо каждый раз:
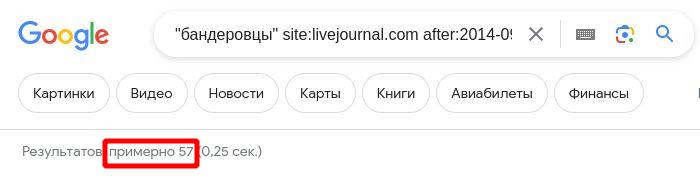
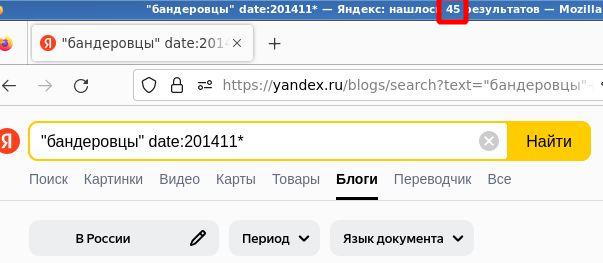
Причем насколько примерно это “примерно” нигде не сообщается. Что может быть хуже для измерительного прибора, чем неизвестная точность? На этот почти риторический вопрос есть ответ – случайная погрешность в сотни процентов, причём не с нормальным (не Гауссовым) распределением. Проведём простой эксперимент. Будем искать “Яндексом” дисфемизм “бандеровцы” в блогах за ноябрь 2014 года. Будем повторять этот запрос несколько раз в течении одного дня. Я получил следующие значения количества результатов: 987, 987, 45, 2000, 1000, 45, 2000. Несколько скриншотов в подтверждение:
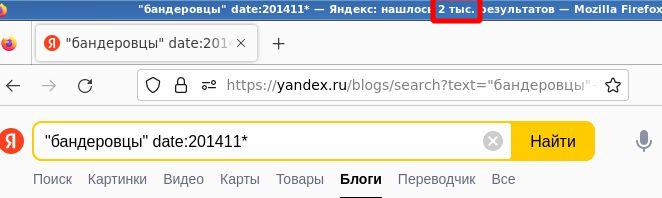
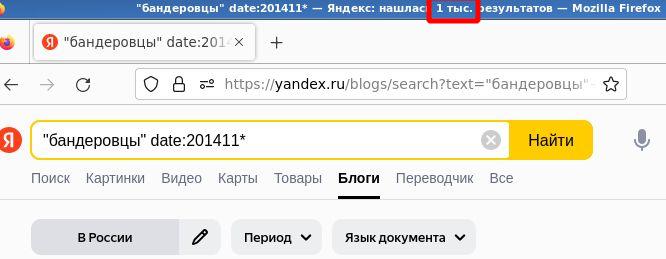
Результаты для того же слова за май 2014-го: 565, 564, 102, 117, 114, 358, 194.
За сентябрь: 590, 584, 497, 1, 2, 375, 498, 534 . Это не опечатка – 1 и 2 было тоже.
Что примечательно, в отличии от “Google”, “Яндекс” не пишет слово “примерно” рядом с результатом. Может быть есть определённое время суток или фазы Луны, когда количество результатов хотя бы примерно соответствует реальности, и тогда там появляется это слово?
В любом случае – я не знаю как можно работать с таким измерительным прибором. Мне кажется он не очень подходит для нужд рассматриваемого исследования. Если, конечно, исследование не имеет цели продемонстрировать набор случайных чисел примерно правильного тренда.
3. Сбор и обработка данных.
Вот что авторы пишут о своей методике сбора данных (выделено мной):
“С помощью инструментария “Яндекс. Поиск по блогам” в течение двух недель мы проводили ежедневные замеры активности всех предварительно отобранных слов. Запросы формулировались на русском и украинском языках (например, [свидомый и свiдомий]) и с учетом вариативности написания, например [бандеровец и бендеровец], также мы стремились избежать омонимии. Данные по количеству воспроизведений лексем фиксировались с шагом в одну неделю.”
Из сказанного прямо следует, что каждый день они проводили поиск по всем словам. Значит у них есть несколько измерений для каждого слова, не меньше 10 (по числу рабочих дней в двух неделях). Авторы не пишут о причинах выбора такой методики и не раскрывают сырых данных. Можно предположить что они решили провести серию измерений для каждого слова как раз по причине “вариативности” результатов поисковой системы, о которой я писал выше. Что гораздо хуже — они ничего не пишут об обработке результатов измерений. Вообще ни слова. Для научной статьи это весьма необычно и, мягко говоря, не добавляет доверия конечным результатам.
4. Боты и тролли.
В статье нет ни слова о ботах и троллях, хотя они вполне могли бы оказать заметное влияние на результаты исследования. Уже в 2013-м об организациях интернет троллей писали в газетах [3]. Пользователи “livejournal” составляли списки ботов для борьбы с ними [4]. Мне неизвестно какой процент аккаунтов в русскоязычной блогосфере приходится на долю ботов и троллей. Но по мнению исследователей в англоязычных социальных сетях, даже если их число на самом деле невелико, боты могут оказывать огромное влияние, а некоторые из них могут оказать существенное влияние на формирование онлайн-общения. Например, одно исследование Университета Карнеги-Меллона, анализирующее распространение лжи о COVID-19 в 2020 году, показало, что из 50 самых влиятельных ретвиттеров 82% были ботами [5]. Таким образом можно сказать, что по крайней мере часть динамики дисфемизмов в интернете определяется не естественными процессами в обществе, а результатом совещаний на планёрках пропагандистов.
5. Пропаганда.
Фарида Курбангалеева работала ведущей программы «Вести» на канале «Россия 1» с 2007 по 2014 год. Вот что она рассказывает:
“А началось все с событий на Майдане. … Я тогда писала текст и называла протестующих протестующими, и мой непосредственный начальник в жесткой форме по телефону сказал, чтобы я больше так не писала, а называла их «духовными наследниками Степана Бандеры». […] Я помню, как совершенно нормально стало называть украинские власти хунтой. Практически все мои коллеги в своих текстах писали «хунта, хунта, хунта».” [6]
Централизованная пропаганда фактически навязывала “язык вражды” в это время и, разумеется, оказывала влияние на его динамику в интернете. Про это в статье также ничего не сказано, как и не сделано никаких попыток хотя бы оценить это влияние. Исключение составляют только пара противоречивых и спорных предложений.
Авторы пишут, что, цитата:
“Он [«язык вражды»] изменяется, подстраиваясь под интенсивность обсуждения конфликта в СМИ и соцсетях. […] Популярность «языка вражды» среди интернет-пользователей связана с наиболее резонансными эпизодами конфликта, получающими максимальное освещение в СМИ. Попытки искусственно повысить языковую агрессию оказываются неэффективными.”
После этого авторы приводят пример попытки неудачного повышения путём флэшмоба. То, что умелой профессиональной массовой пропагандой можно “искусственно повысить языковую агрессию” доказано многократно всей человеческой историей, в том числе российской, а до этого советской. Это настолько очевидный факт, что вряд ли кто-то всерьёз будет это оспаривать, кроме авторов этой статьи. При этом они сами пишут о влиянии событий “максимально освещаемых в СМИ”. Но большинство россиян узнавали о событиях конфликта из контролируемого правительством телевидения. Что именно там “максимально освещают”, и, самое главное, как — определяет ограниченный круг людей. И тому есть прямые свидетельства людей, участвовавших в этом.
6. Курица или яйцо.
Авторы всерьёз рассуждают на тему первичности — сначала ругань потом драка или наоборот. И на основе своего мониторинга делают вывод, цитата:
“Таким образом, массовое использование дисфемизмов не предшествует акту агрессии (как считает Ханна Сигал), а следует за ним.”
Можно только позавидовать авторам, не имеющим жизненного опыта в ругани и драках. К сожалению, не всем так повезло, и большинство взрослых людей расскажут вам множество реальных историй, когда ругань с обзывалками была до драки, во время драки и после неё. Во всех возможных комбинациях. И когда драка была из-за обзываний, и когда нападающие обзывались больше чем жертвы, и наоборот. В том числе, когда в конфликт было вовлечено большое количество людей. На youtube, кстати, достаточно таких видео.
В любом случае, нельзя на примере одного конфликта делать глобальные выводы о каких-либо закономерностях. Если же это ещё и преподносится как вывод научного исследования, то это попросту непрофессионально.
7. Заключение.
Авторы, по факту, измерили нечто, являющееся суммой нескольких факторов, не указывая и не разделяя их. Причём измерительным устройством для этого не предназначенным, с неизвестной погрешностью. Ни сырые данные, ни методика их обработки не раскрыта. На основе этого одного случая были сделаны далеко идущие выводы, очевидно не соответствующие наблюдаемой реальности. Пожалуй единственным настоящим результатом исследования, было подтверждение некоего тренда нарастания “языка вражды” после начала конфликта, что, однако, является тривиальным общеизвестным фактом.
Библиография
1. Дарья Радченко и Александра Архипова. “Укроп и ватник: ‘язык вражды’ российско-украинского конфликта как нападение и защита.” Ab Imperio 2018, no. 1 (2018): 191–220. https://doi.org/10.1353/imp.2018.0007. Полный текст доступен по этой ссылке.
2. Левада-Центр. “Российский медиа-ландшафт: телевидение, пресса, Интернет,” June 17, 2014. Ссылка.
3. Александра Гармажапова. “Где Живут Тролли. И Кто Их Кормит. Специальный Репортаж Из Офиса, в Котором Вешают Лапшу в Три Смены — Новая Газета.” Accessed October 26, 2023. https://novayagazeta.ru/articles/2013/09/07/56253-gde-zhivut-trolli-i-kto-ih-kormit.
4. jozhik. “Объявление Войны Ольгинским Ботам!” ЖУРНАЛ ЗЛОГО ЙОЖИКА (blog), March 12, 2015. https://jozhik.livejournal.com/585080.html.
5. Dang, Sheila, Katie Paul, and Dawn Chmielewski. “Focus: Do Spam Bots Really Comprise under 5% of Twitter Users? Elon Musk Wants to Know.” Reuters, May 14, 2022, sec. Technology. https://www.reuters.com/technology/do-spam-bots-really-comprise-under-5-twitter-users-elon-musk-wants-know-2022-05-13/.
6. Зеркало. “«Я сейчас рассказываю и думаю, какая же это блевотина невероятная». Большое интервью с экс-ведущей российских «Вестей»,” June 23, 2023. https://news.zerkalo.io/world/41942.html.